Spring Batch používá šest tabulek:
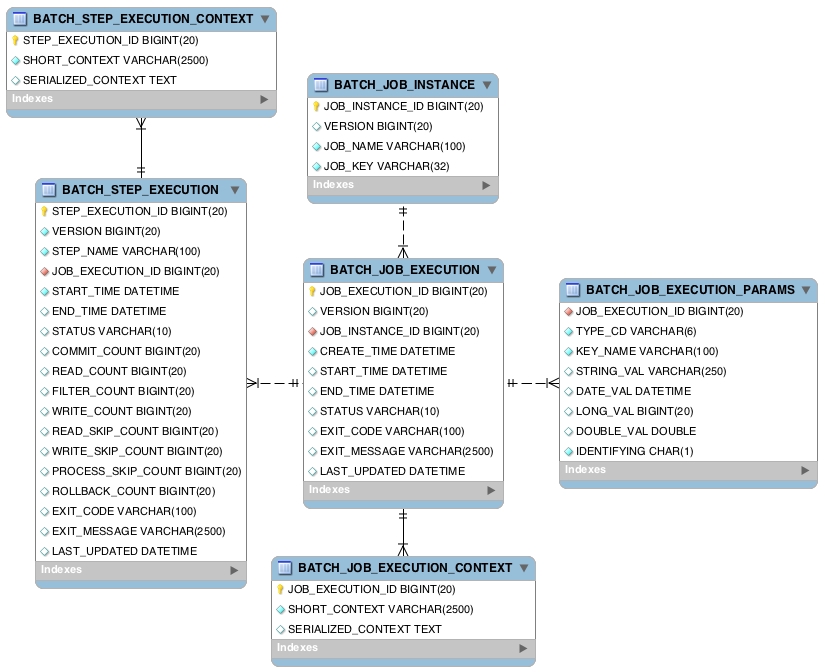
Spring Batch obsahuje inicializační SQL skripty pro většinu populárních databází (více v tomto příspěvku). Spring Boot dokáže detekovat databázi a spustit správný skript při startu aplikace. Pokud chcete, aby Spring Batch vytvořil potřebné tabulky, přidejte do konfiguračního souboru
spring.batch.initialize-schema=always
Vypnutí této funkcionality
spring.batch.initialize-schema=never
Pokaždé, když bude 9 vteřina
9 * * * * ?
2020-07-04 13:16:09.057000
2020-07-04 13:14:09.011000
2020-07-04 13:13:09.004000
Pokaždé, když bude 20 mituta a 5 vteřina
5 20 * * * ?
2020-07-04 13:20:05.109000
Pokaždé, když bude 18 vteřina, 34 minuta a 13 hodina
18 34 13 * * ?
Pokaždé, když bude 0 vteřina, 50 minuta, 13 hodina a 24 den v měsíci
0 50 13 24 * ?
Takový to kron string se dá použít například při plánování jobů ve spring batch:
application.properties -> app.jobs.cron: 0 35 13 24 *
konfigurace jobu -> @Scheduled(cron = "\${app.jobs.cron}")
Spring Batch používá 6 tabulek, pro ukládání dat:
batch_job_execution batch_job_execution_context batch_job_execution_params batch_job_instance batch_step_execution batch_step_execution_context
Tyto tabulky vytvoříte přidáním následujícího řádku do souboru application.properties:
spring.batch.initialize-schema=always
Zdroj: stackoverflow.com/…-auto-create-batch-table
Nedávno jsem prováděl změny verze Javy na projektu, který používá Spring Boot. Měnil jsem verzi Javy z verze 8 na verzi 11. Nebylo to až tak strašné, jak jsem čekal (spíše naopak), přesto se ale některé komplikace objevily. V tomto příspěvku budu postupovat od chyby k chybě, tak jak se u mě objevovaly.
V tomto příspěvku budeme pokračovat v tomto projektu. Aktuálně máme prázdny projekt v Eclipse IDE, který lze spustil. Přidáme si do něj jednoduchý job, který bude mazat soubor. Pro definování nových tříd (beans) použijeme java configuraci.
BeanConfig.java
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import cz.vitfo.batch.processing.DeleteFileTasklet;
@Configuration
@EnableBatchProcessing
@ComponentScan("cz.vitfo")
public class BeanConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DeleteFileTasklet deleteFileTasklet;
@Bean
public Job myJob() {
return jobBuilderFactory.get("myJob")
.start(deleteFileFromDirectoryStep())
.build();
}
@Bean
public Step deleteFileFromDirectoryStep() {
return stepBuilderFactory.get("deleteFileFromDirectoryStep")
.tasklet(deleteFileFromDirectoryTasklet())
.build();
}
@Bean
public Tasklet deleteFileFromDirectoryTasklet() {
return deleteFileTasklet;
}
}
V tomto příspěvku si vytvoříme Spring Boot projekt se Spring Batch. V dalších číslech pak budeme s tímto projektem pokračovat. Nejdříve si nechte vygenerovat projekt pomocí Spring Initializr. Přidejte závislost na Batch.
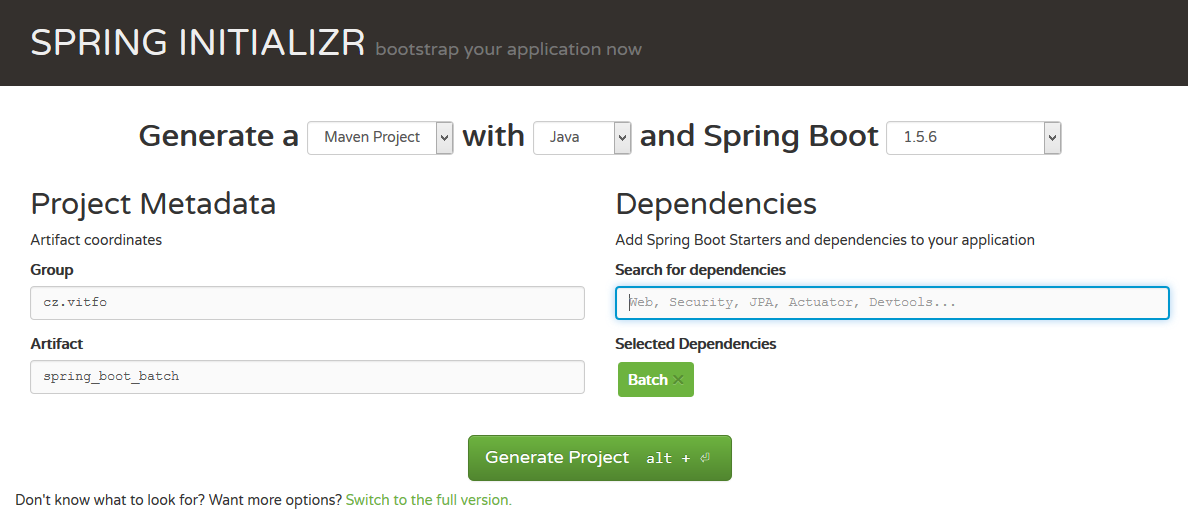
Stáhněte si zip s vygenerovaným projektem, rozbalte jej a naimportujte do Eclipse IDE (File -> Import… -> Maven -> Existing Maven Projects -> najít rozbalený projekt -> Finish). Projekt spusťte (pravým na projekt -> Run As -> Java Application, nebo pokud používáte STS tak Spring Boot App). Měli byste dostat následující chybu:
Error starting ApplicationContext. To display the auto-configuration report re-run your application with 'debug' enabled. 2017-09-05 13:49:01.364 ERROR 14088 --- [ main] o.s.b.d.LoggingFailureAnalysisReporter : *************************** APPLICATION FAILED TO START *************************** Description: Cannot determine embedded database driver class for database type NONE
O této chybě již byla řeč v tomto příspěvku. Přidejte tedy do pomu závislost:
<dependency> <groupId>org.hsqldb</groupId> <artifactId>hsqldb</artifactId> </dependency>
Pokud projekt spustíte nyní, vše by mělo proběhnout v pořádku.
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v1.5.6.RELEASE) 2017-09-05 13:53:11.461 INFO 12504 --- [ main] c.v.s.SpringBootBatchApplication : Starting SpringBootBatchApplication on W2AB00HL with PID 12504 (C:\Users\jd99517\Documents\STS\WorkspaceSpringBatch\spring_boot_batch\spring_boot_batch\target\classes started by JD99517 in C:\Users\jd99517\Documents\STS\WorkspaceSpringBatch\spring_boot_batch\spring_boot_batch) 2017-09-05 13:53:11.464 INFO 12504 --- [ main] c.v.s.SpringBootBatchApplication : No active profile set, falling back to default profiles: default 2017-09-05 13:53:11.510 INFO 12504 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@3bbc39f8: startup date [Tue Sep 05 13:53:11 CEST 2017]; root of context hierarchy 2017-09-05 13:53:12.240 INFO 12504 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup 2017-09-05 13:53:12.250 INFO 12504 --- [ main] c.v.s.SpringBootBatchApplication : Started SpringBootBatchApplication in 1.049 seconds (JVM running for 1.64) 2017-09-05 13:53:12.250 INFO 12504 --- [ Thread-2] s.c.a.AnnotationConfigApplicationContext : Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@3bbc39f8: startup date [Tue Sep 05 13:53:11 CEST 2017]; root of context hierarchy 2017-09-05 13:53:12.251 INFO 12504 --- [ Thread-2] o.s.j.e.a.AnnotationMBeanExporter : Unregistering JMX-exposed beans on shutdown
JobRepository je používána pro základní CRUD (Create, Read, Update, Delete) operace nad určitými objekty (domain objekty) frameworku Spring Batch. Jednoduše řečeno, Spring Batch si zde ukládá potřebné informace o jobech (Job) a jednotlivých krocích jobu (Step). V případě, že tyto informace nepotřebujeme, nabízí Spring Batch in-memory implementaci pomocí mapy. Tento způsob jsem zatím používal ve všech předchozí Spring Batch příkladech.
<bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean"> <property name="transactionManager" ref="transactionManager" /> </bean>
V případě, že chceme batch objekty ukládat, je potřeba nadefinovat data source. Zde je příklad pro databázi PostgreSQL.
<beans:bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <beans:property name="driverClassName" value="org.postgresql.Driver" /> <beans:property name="url" value="jdbc:postgresql://localhost:5432/database" /> <beans:property name="username" value="username" /> <beans:property name="password" value="password" /> </beans:bean>
Za database, username, password zadejte validní data.
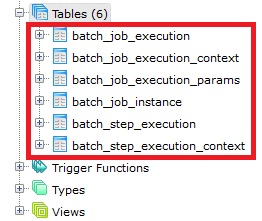
Pokud máte novou databázi, určitě v ní nebudete mít vytvořeny potřebné tabulky:
Doposud jsem v příspěvcích k Spring Batch používal xml konfiguraci. Spring ale umožňuje též konfigurovat pomocí java tříd. V tomto příspěvku ukáži jednoduchý Spring Batch projekt, který bude používat java config. Projekt bude stejný jako v tomto příspěvku, pouze bude místo xml používat java konfiguraci.
Struktura projektu
│ pom.xml
│
└───src
├───main
│ └───java
│ └───batch
│ AppConfig.java
│ Employee.java
│ ExecuteBatchJob.java
│ ResultWriter.java
│
└───resources
reportCS.csv
AppConfig.java předstaje java třídu obsahující konfiguraci.
Tento příspěvek volně navazuje na článek Spring Batch 3. díl, ve kterém byla ukázána práce s chunk a definovanými objekty reader, processor, writer. V dnešním příspěvku se seznámíme s tím, jak načítat data z .csv souboru pomocí FlatFileItemReaderu. FlatFileItemReader je ItemReader, který čte řádky ze vstupu. Vstup je určen elementem <property name="resource" value="classpath:reportCS.csv"/>. V tomto případě se bude číst ze souboru reportCS.csv, který se nachází na classpath.
Prostý databázový soubor (též plochý databázový soubor, anglicky flat file database) je jednoduchá databáze (většinou tabulka) uložená v textovém souboru ve formě prostého textu. Takový soubor může mít příponu například .txt, .ini, .conf, ale i .dbf apod. Zdroj: cs.wikipedia.org
Zde je ukázka FlatFileItemReaderu.
<bean id="csvFileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader"> <property name="resource" value="classpath:reportCS.csv"/> <property name="encoding" value="UTF-8"/> <property name="linesToSkip" value="1"/> <property name="lineMapper"> <bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"> <property name="lineTokenizer"> <bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"> <property name="names" value="Name,Surname,Location,Job,Earning"/> </bean> </property> <property name="fieldSetMapper"> <bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"> <property name="prototypeBeanName" value="employee"></property> </bean> </property> </bean> </property> </bean>
resource: zdroj dat pro čtení
encoding: kódování zdrojového souboru
linesToSkip: nastaví počet řádků souboru, které se mají přeskočit před začátkem čtení
lineMapper: nastaví line mapper, mapování načteného řádku
Číst dálNačtení csv souboru pomocí FlatFileItemReader ve Spring Batch